Questo post si affianca all’articolo “Data Scientist Uno, nessuno e centomila” scritto nel numero 2/2017 della rivista Archimede da Andrea Capozio, Valerio Capozio e Davide Passaro.
L’articolo (disponibile a breve a pagamento qui) affronta la professione emergente del Data Scientist individuandone gli aspetti caratteristici. Nel testo si evidenziano le competenze trasversali richieste da questa figura quali quelle di matematica e informatica (linguaggi di alto livello come R e Python, conoscenza di ambiti come quelli del Machine Learning, dell’ottimizzazione, ecc…).
Dal punto di vista didattico nelle pagine della rivista si evidenzia l’importanza di presentare, in vista anche dell’orientamento universitario e delle possibili scelte lavorative, questa “nuova professione” che rappresenta un ulteriore possibilità lavorativa per i laureati in discipline scientifiche quali matematica, fisica, ingegneria, statistica.
In questo post, a completamento di quell’articolo, presentiamo alcuni spunti e riferimenti utili per avvicinarsi alla conoscenza del linguaggio R che, insieme con il linguaggio Python, è attualmente uno dei linguaggi più orientati all’analisi dei dati ed alla statistica.
Per gli spunti sul linguaggio Python rimandiamo a questo precedente articolo sempre pubblicato nella rubrica “La Leva di Archimede”.
R, in particolare, è un linguaggio di programmazione (distribuito con la licenza GNU GPL e disponibile nei principali sistemi operativi) nato in modo specifico per l’analisi statistica dei dati. La sua diffusione e l’introduzione di librerie specifiche dedicate a contesti specifici, lo rende un semplice strumento per far sperimentare agli studenti esercizi di analisi dei dati sfruttando i dataset di test facilmente scaricabili in rete.
Tutorial per imparare il linguaggio R e scoprirne le sue potenzialità sono presenti ampiamente in rete. In particolare suggeriamo:
Ovviamente esistono molto video di tutorual online per imparare R come per esempio questo qui sotto (in inglese)
Qui di seguito, invece, presentiamo alcuni esempi tratti dalla dispensa di Riccardo Massafri (disponibile per esempio qui) che utilizza il dataset qui scaricabile.
In questo dataset (che altro non è che un semplice .csv che sta per comma-separated values) sono inseriti circa 200 veicoli caratterizzati ciascuno per tipo di alimentazione, peso, cilindrata, numero di cilindri, ecc…).
L’esercizitazione che si potrebbe proporre agli studenti è quello di aprire il dataset e analizzarlo mostrando i grafici delle varie variabili.
I comando da inserire sulla Console di R per aprire il dataset è il seguente:
> auto <- read.csv("/path_salvataggio_file/auto.csv", row.names = 1)
> #carica i dati "auto"
Per gestire più facilmente i dati e rendere le varie colonne direttamente accessibili si utilizza questa ulteriore istruzione
> attach(auto)
Per esempio è possibile fare il grafico in cui si confrontano il peso (che a essere pignoli con chi ha creato il dataset sarebbe stato meglio indicare con la massa) dell’auto e la corrispondente cilindrata, con la seguente istruzione:
> plot(x = peso, y = cilindrata)
Dal grafico precedente potrebbero nascere, per esempio, tutta una serie di considerazioni didattiche sulla correlazione dei dati ed avere la conferma di quello che gli stessi studenti si potevano aspettare ovvero un legame fra cilindrata e massa della vettura.
Nella dispensa da cui sono presi questi esempi si mostrano le istruzioni per realizzare grafici più “raffinati” in cui, per esempio i punti siano colorati in modo diverso per visualizzare altre caratteristiche dal dataset (per esempio il tipo di trazione della auto). Rimandiamo a questa, quindi, per un maggiore dettaglio.
Una semplice istruzione da presentare che permette delle riflessioni sui dati è la funzione boxplot:
> boxplot(cilindrata)
Con questa istruzione, infatti, è mostrato il boxplot di ciascuna variabile del campione realizzando un grafico che rappresenta le quantità: minimo, massimo, primo, secondo (mediana) e terzo quartile. Questo diagramma fornisce informazioni sulla sulla variabilità che sulla asimmetria di una distribuzione.
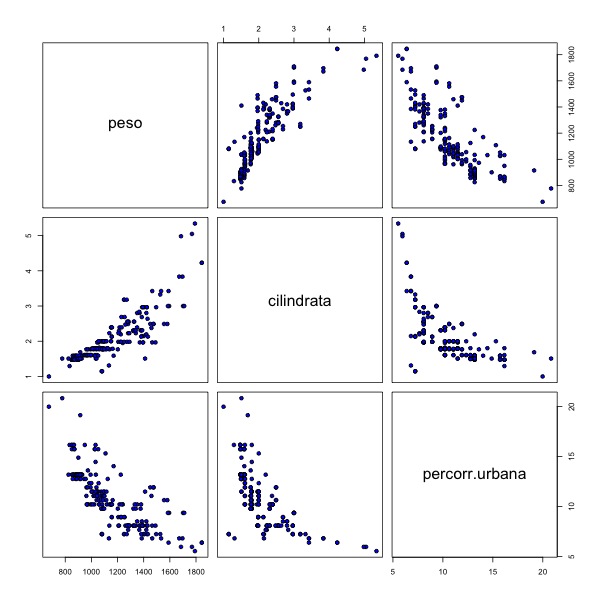
Altra istruzione molto utile è quella che permette di visualizzare i grafici delle variabili confrontate a coppie (scatterplot). Il comando da utilizzare è semplicemente:
> pairs(x = auto, pch = 21, bg = 4)
Per ottenere un grafico più leggibile e sensato si possono far selezionare agli studenti un sottoinsieme di variabili. Per esempio:
Osservando un gafico di questo tipo, tantissimi sono gli spunti che si potrebbero sollecitare o che potrebbero uscire dalle intuizioni degli studenti. Tanto per fare un esempio si potrebbe osservare che il fatto che all’aumentare del peso aumenti la cilindrata e quindi c’è una correlazione positiva, mentre per peso vs percorrenza urbana la correlazione è negativa.
Roberto Natalini [coordinatore del sito] Matematico applicato. Dirigo l’Istituto per le Applicazioni del Calcolo del Cnr e faccio comunicazione con MaddMaths!, Archimede e Comics&Science.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.


 conoscenza del linguaggio R che, insieme con il linguaggio Python, è attualmente uno dei linguaggi più orientati all’analisi dei dati ed alla statistica.
conoscenza del linguaggio R che, insieme con il linguaggio Python, è attualmente uno dei linguaggi più orientati all’analisi dei dati ed alla statistica.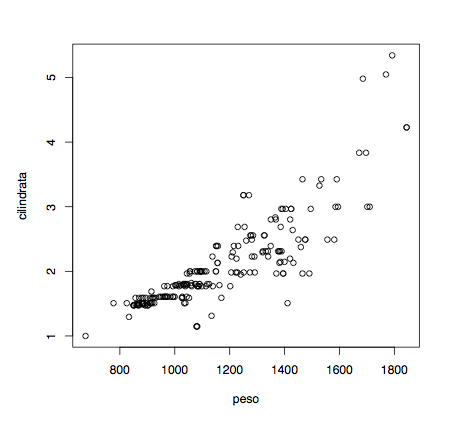

















 to Watch: MathsWithKala")
")