L’intelligenza artificiale (IA) è un modo semplificato di indicare un insieme di strumenti computazionali costruiti per svolgere compiti complessi in campo cognitivo. Qual è il ruolo di questi strumenti nella matematica attuale e futura? Cambierà il nostro modo di fare matematica e di immaginare nuovi filoni di ricerca? Seconda puntata di Giovanni Naldi su alcuni aspetti legati all’uso dei computer e dell’IA in matematica. La prima la trovate qui.
Dalla Lavagna al codice e ritorno
Come trovare un linguaggio simbolico universale capace di esprimere ogni pensiero logico? I tentativi sono stati molti, diversi i progetti, vari i desiderata ed i risultati. Uno degli aspetti della matematica, e successo indiscusso della logica moderna, è la dimostrazione che le definizioni e le prove matematiche possono essere rappresentate in sistemi assiomatici formali. Tra i primi di questi sistemi possiamo annoverare l’assiomatizzazione della teoria degli insiemi di Zermelo, introdotta nel 1908, e il sistema della teoria dei tipi, presentato da Russell e Whitehead nei Principia Mathematica nel 1911. Questi sistemi ebbero un tale successo che Kurt Gödel iniziò il suo famoso saggio del 1931 sui teoremi di incompletezza commentando la loro efficacia. Da questo punto di vista i risultati dello stesso Gödel sono sconcertanti: “indipendentemente dai sistemi a cui aderiamo ora o in qualsiasi momento futuro, ci saranno sempre questioni matematiche, persino sugli interi, che non possono essere risolte su quella base, a meno che i metodi non siano di fatto incoerenti”. Ma il messaggio positivo trasmesso dall’introduzione è quasi altrettanto sorprendente: per quanto incompleti possano essere, i metodi che usiamo possono nondimeno essere formalizzati.
In effetti, con lo sviluppo dei primi assistenti automatici per le dimostrazioni, intorno al 1970, è diventato possibile realizzare tale formalizzazione nella pratica. Ora possiamo scrivere definizioni, teoremi e prove matematiche in linguaggi idealizzati, come i linguaggi di programmazione, che i computer possono interpretare e controllare. Lo sforzo attuale si concentra sullo sviluppo di depositi digitali di conoscenza matematica in modo tale che che possano essere elaborati, verificati, condivisi e ricercati con mezzi informatici.
In particolare sono sorti vari sistemi automatici di verifica come Lean, Coq o Agda. Con tali sistemi non solo è possibile arrivare ad una sorta di certificazione sicura della validità di una dimostrazione ma è possibile cercare di utilizzare tali sistemi come collaboratori per qualche passo in più rispetto al risultato sotto analisi. Per esempio è possibile “indebolire” le ipotesi di un teorema e osservare dove la dimostrazione eventualmente si inceppa, oppure è possibile esplorare linee dimostrative differenti per lo stesso teorema o proposizione: una esplorazione guidata.
Ma dove risiede il segreto di tali sistemi? Lean e strumenti affini poggiano su una struttura chiamata teoria dei tipi dipendenti (nello specifico, Lean utilizza il “calcolo delle costruzioni induttive”). In tale teoria si tratta ogni entità matematica come un “oggetto” appartenente a uno specifico “tipo”. Potremmo immaginarla come una sorta di pignola etichettatura logica di ogni oggetto matematico. In particolare nella Teoria dei Tipi ogni oggetto appartiene a una propria “categoria”, chiamata appunto Tipo, che ne definisce le regole di utilizzo.
Il Numero 7, per esempio, è di tipo N (Numero Naturale), un’addizione è una funzione che prende due tipi N e restituisce un tipo N. Il controllo è piuttosto stretto, supponiamo, per esempio, di definire il tipo “lista di m numeri interi” e di considerare un programma per ordinare tale lista. Se per qualche motivo, errore od evento, il programma ordinasse gli elementi della lista ma ritornasse una lista con un numero di elementi inferiore o superiore ad m, il sistema segnala un errore: il risultato non è dello stesso tipo del risultato atteso (lista di m numeri interi). L’errore si palesa come un errore nella compilazione del codice LEAN, ovvero una “messa in atto” della dimostrazione.
Una proposizione matematica (ad esempio “i numeri primi sono infiniti”) è vista come un tipo. Se riesci a costruire un oggetto che “abita” quel tipo, allora hai dimostrato il teorema. Se il tipo è vuoto, il teorema non è dimostrato o è falso. Lean, e sistemi simili, implementano una versione pratica di questa idea (una forma di “calcolo delle costruzioni” con tipi induttivi), fornendo anche una libreria ricca di risultati già formalizzati (Mathlib), un sistema di tattiche per costruire prove in modo interattivo e un elaboratore che aiuta a inferire dettagli sintattici. Il vantaggio per la pratica matematica è doppio: le dimostrazioni diventano controllabili meccanicamente (eliminando ambiguità formali) e il linguaggio dei tipi permette di esprimere proprietà sofisticate (per esempio dipendenti da numeri o strutture), rendendo Lean adatto sia alla verifica formale di teoremi classici sia allo sviluppo di teorie matematiche complesse.
Verificare una dimostrazione è certamente molto più semplice che crearne una. Questo aspetto di “verifica” verso “creazione” è comune anche in altri ambiti. Per esempio in informatica: stessa necessità di verifica formale (si pensi ad un software che controlla la logistica di un aeroporto piuttosto che le operazioni finanziarie), stessa domanda sulla possibilità di generare codice automaticamente. Questo spiega anche in buona parte l’interesse per le questioni matematiche viste come palestra adeguata, e non troppo “pericolosa”, per affrontare verifica e creazione di codice.
Tornando alla complessità, verificare se una lista di numeri è ordinato in qualche senso, crescente o decrescente, è piuttosto semplice: di fatto basta percorrerla. Trovare un algoritmo per l’ordinamento è più complicato, trovarne uno più rapido ed efficiente è un altro passo verso la difficoltà. Verificare se una assegnazione di valori (vero o falso) di variabili logiche in una formula con connettori “and”, “or”, “not” rende la formula vera è semplice (tempo necessario per la valutazione di tutte le espressioni logiche). Trovare una assegnazione, ovvero creare una soluzione, è difficile, anzi molto difficile essendo nella classe dei problemi NP-completi.
Se si fosse provato ad interrogare i primi modelli linguistici di grandi dimensioni (LLM) per questioni semplici o note, per esempio ricavare l’espressione per il calcolo delle radici di una equazione di secondo grado o dimostrare che i numeri primi sono infiniti, le risposte contenevano diversi errori logici. L’impressione era di essere di fronte ad uno studente che cercava di arrampicarsi sugli specchi arrivando a qualche conclusione con il prompt che ti guardava inespressivo.
Da allora molti progressi sono stati fatti. Oggi abbiamo diversi sistemi in grado, per esempio, di trovare la soluzione dei problemi dell’olimpiadi della matematica, attirando l’attenzione di diversi matematici: abbiamo uno strumento che possa aiutarci nel lavoro? Come si posizionano questo tipo di strumenti rispetto al lavoro del Matematico/a in carne ed ossa? Ci sono delle analogie? Questioni interessanti ed attualmente aperte.
Gli LLM standard (come GPT-4 o Gemini senza strumenti esterni) sono un motore statistico: predicono la parola (meglio il token) successiva basandosi su probabilità relative al contesto ed altre variabili e su dati preparati (spesso ci si scorda di menzionare il ruolo cruciale dell’embedding che associa in modo opportuno/semantico ad ogni token un vettore, posizionandolo in uno spazio geometrico multidimensionale). In matematica, questo porta a inventare teoremi inesistenti, a errori logici con passaggi che sembrano corretti ma contengono una falla che invalida tutto, alla mancanza di auto-correzione (L’LLM non sa di aver sbagliato finché qualcuno non glielo dice).
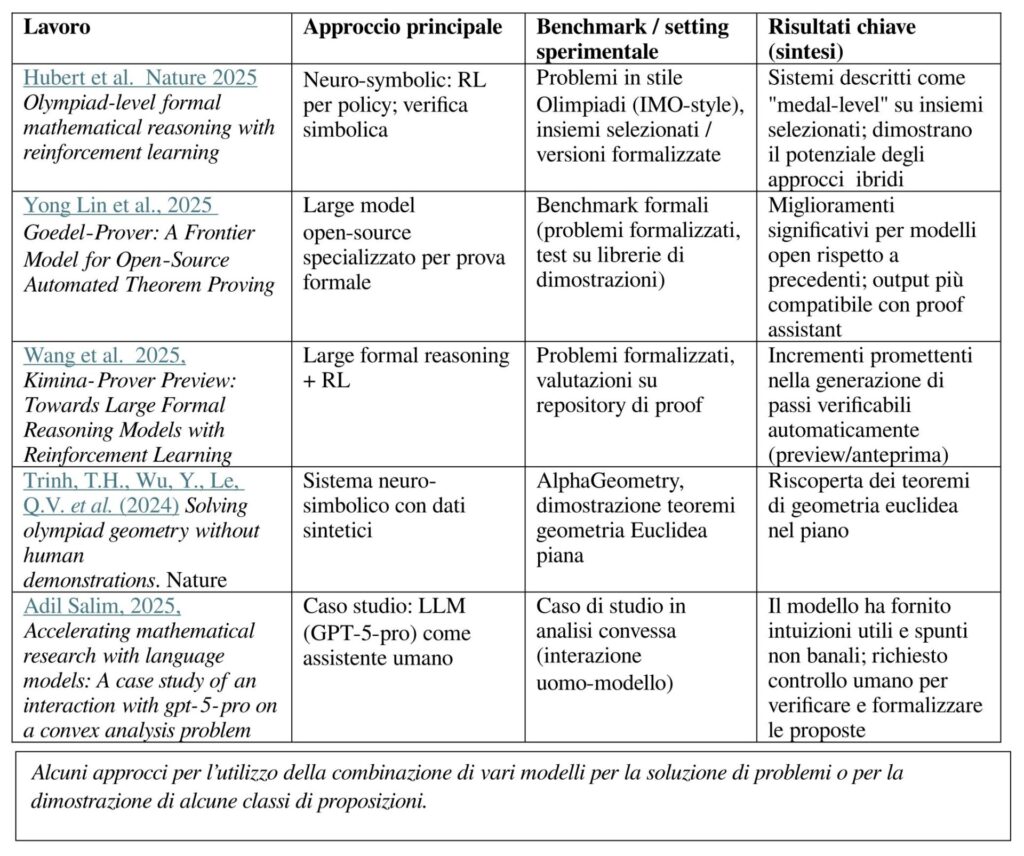
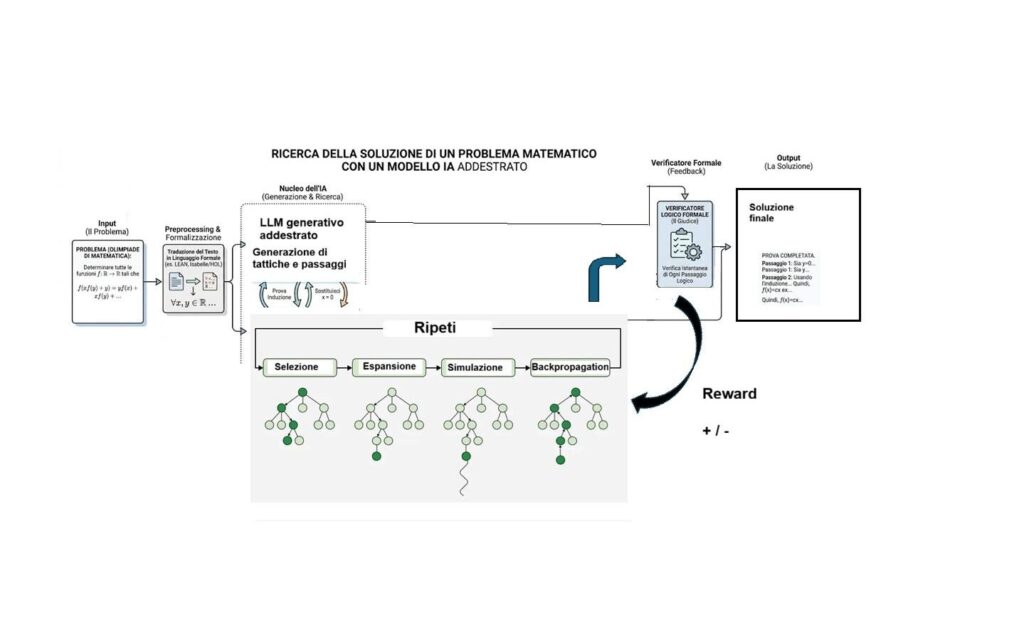
Come passare dalla verifica alla costruzione di una dimostrazione? L’approccio che oggi viene considerato lo stato dell’arte è un sistema ibrido che combina LLM (Large Language Models), verificatori formali (come Lean), il reinforcement learning (RL) e il MCTS (ricerca ad albero Monte Carlo).
Nel reinforcement learning, o apprendimento per rinforzo, si impara sbagliando. Invece di dare in pasto ad un modello miliardi di esempi già pronti (come accade nel Deep Learning tradizionale), nel RL lo lasciamo libero di agire in un “ambiente” e osserviamo cosa succede: insomma è il metodo del “bastone e della carota” applicato agli algoritmi. È un metodo molto usato per sviluppare programmi in grado di giocare a scacchi o a go adottando strategie vincenti partendo da una certa posizione.
Per capire come funziona, immaginiamo un robottino che deve imparare a uscire da un labirinto. Attori principali: l’agente protagonista (il nostro software che controlla il robot), L’ambiente (tutto ciò che circonda l’agente, ovvero il labirinto), L’azione (quello che l’agente può fare, andare a destra, sinistra, avanti o indietro), Il premio (reward, Il feedback che l’agente riceve, se trova l’uscita riceve un premio positivo; se sbatte contro un muro riceve una penalità). Come avviene l’apprendimento? All’inizio l’agente non sa nulla, si muove a caso, sbattendo ovunque. Tuttavia, il suo obiettivo è uno solo: massimizzare il punteggio totale nel lungo periodo. Dopo molti tentativi, l’algoritmo inizia a capire quali sequenze di azioni portano alla “carota” e quali al “bastone”. Sviluppa così una strategia (chiamata policy) per risolvere il problema nel modo più efficiente possibile.
In un modello IA che ha come obiettivo risolvere problemi per le olimpiadi della matematica o altro tipo di problemi matematici, l’allenamento del modello IA si basa su un ciclo iterativo. Inizialmente, un modello linguistico (LLM) agisce come un “generatore di idee”, proponendo diverse possibili scomposizioni o passaggi logici per risolvere un problema. Per fare questo lo spazio delle premesse è solitamente piccolo (conoscenze di base di algebra, combinatoria, geometria) e l’allenamento viene fato su molti problemi simili e spesso, attualmente, generati sinteticamente.
Poiché la matematica non ammette ambiguità, queste proposte vengono passate a un verificatore formale (come Lean o Isabelle) e/o a un sistema di controllo simbolico, che agisce come un giudice imparziale in grado di confermare se ogni singolo passaggio è matematicamente corretto. I tentativi che portano alla soluzione corretta ricevono un premio (reward), che viene utilizzato tramite il reinforcement learning per aggiornare il modello. In questo modo, l’AI non impara solo a “indovinare” la risposta, ma affina progressivamente la propria capacità di esplorare solo i percorsi logici più promettenti, scartando i vicoli ciechi e imparando dai propri errori.
Facciamo adesso accomodare il nostro modello IA e somministriamogli un nuovo problema, pronti, via. Cosa accade? Primo passo, il problema deve essere formalizzato (da una persona umana o da qualche sistema automatico). A questo punto entra in gioco l’LLM, allenato per il compito specifico, che invece di provare tutte le strade possibili (troppe anche per lui), genera una lista di “tattiche” promettenti per il tipo di problema, ad esempio: “Prova a procedere per induzione”, “Applica la disuguaglianza di Cauchy-Schwarz”, “Semplifica l’espressione trigonometrica”.
Come si combinano i passi della dimostrazione? Si esplorano le varie possibili ramificazioni attraverso un algoritmo noto come Monte Carlo Tree Search (MCTS). Viene costruito un albero dove ogni “nodo” è uno stato intermedio della dimostrazione. Ogni stato rappresenta la configurazione corrente del problema (obiettivi residui, contesto, ipotesi, stato delle metavariabili). Si genera una azione ovvero una scelta di passo di dimostrazione (una tattica, un’applicazione di regola, una assegnazione). A questo punto avviene la fase di espansione: aggiungere nodi corrispondenti alle possibili tattiche applicabili. Per valutare i nodi si esegue una sequenza di tattiche secondo una politica veloce (euristica o appresa) fino a raggiungere un successo (dimostrazione) o un limite di profondità. A questo punto si premia o meno il percorso seguito, calcolo del “reward”: per esempio 1 se la dimostrazione è raggiunta, 0 altrimenti e punteggi differenziati per progressi parziali. Infine avviene la backpropagation: aggiornare stime di qualità/numero di visite per i nodi lungo il percorso selezionato. In questo caso, la stocasticità si utilizza quando l’LLM non propone un’unica soluzione rigida, ma viene campionato probabilisticamente per generare una varietà di tattiche matematiche.
Una schematizzazione del processo di dimostrazione automatico per un problema di matematica (per esempio del tipo utilizzato nelle olimpiadi della matematica). Un LLM addestrato con problemi simili (anche sintetici) e risultati di matematica a livello di scuola secondaria superiore, generare molte possibile tattiche dimostrative che vengono codificate attraverso un grafo che viene ampliato ed esplorato seguendo un principio di apprendimento rinforzato. Ogni passaggio viene verificato da un sistema automatico (per esempio Lean).
Ci siamo dilungati, forse troppo, riguardo ad una descrizione di massima di questi strumenti per sottolineare che, alla fine del processo, capire davvero come una eventuale soluzione sia stata generata sia estremamente complicato se non impraticabile. Certamente ci troviamo di fronte ad uno studente con alle spalle un enorme quantità di problemi e procedimenti memorizzati che vengono combinati e verificati: non si tratta del “guizzo” del partecipante alla competizione olimpica ma di una ricerca molto ben strutturata e intelligente su una base improponibile se non per una infrastruttura informatica molto grande. In questa esplorazione possono sorgere anche strade che solitamente non si guardano e percorrono.
Ci troviamo nella situazione di avere diversi esperimenti, anche molto interessanti, ma non abbiamo idea del perché si abbiano dei risultati positivi. Uno dei primi tentativi di indagine sistematica si deve a Terence Tao che, insieme a premi Nobel, vincitori di medaglia Turing e di medaglia Fields, ha fondato SAIR — the Foundation for Science and AI Research. Questa istituzione è nata per collegare ricerca scientifica di base e sviluppo dell’IA, con l’obiettivo di accelerare la scoperta scientifica (modellizzazione, esperimenti computazionali, automazione delle analisi) e nel contempo costruire una base scientifica più solida per l’IA.
Un aspetto, raramente citato, ma che SAIR vorrebbe affrontare, è la sostenibilità. Lo sviluppo dell’IA comporta costi ambientali e sociali significativi, legati al consumo di energia, acqua e risorse materiali. Finora, nessun grande modello ha compensato pienamente tali costi. Il nostro cervello consuma circa 20 Watt ed anche mettendo insieme tutti i matematici attivi del mondo non si arriva al consumo di un centro dati necessario per l’IA. Ci sono dei limiti fisici evidenti da considerare. La parte LLM del modello AlphaProof che ha affrontato i problemi dell’olimpiadi della matematica del 2024, durante i giorni della competizione, ha generato milioni di varianti correlate e problemi più semplici partendo dal testo originale. Mentre le ragazze e i ragazzi durante le Olimpiadi hanno avuto 4 ore e mezza al giorno per tre problemi, AlphaProof, per alcuni problemi non tutti, ha continuato a generare e verificare soluzioni per diversi giorni consecutivi di calcolo parallelo prima di convergere sulla dimostrazione formale corretta per i problemi superati. Alcuni problemi sono risultati ostici e non risolti, per altri si è arrivati ad una soluzione parziale.
Alcuni dei problemi dell’olimpiadi della matematica del 2024 affrontati dal modello alphaproof. In questo caso, dopo almeno un giorno di elaborazione, il Problema P1 è stato risolto per metà, il problema P2 completamente mentre per P3 non si avevano progressi. E’ stato osservato che per P3 si è avuta una notevole difficoltà nella formalizzazione e richiedeva una certa dose di creatività.https://www.youtube.com/watch?v=TFBzP78Jp6A&t=4839s
Dei tentativi ci sono: si cerca di affiancare una ricerca in rete opportuna per diminuire il carico computazionale sul modello IA in uso. Per esempio, per ambiti specifici come la matematica, si cerca di introdurre la distillazione della conoscenza (knowledge distillation). Si tratta di una tecnica di addestramento in cui un modello di grandi dimensioni, potente e complesso (chiamato modello “Insegnante” o teacher), trasferisce le sue capacità a un modello più piccolo, leggero ed efficiente (chiamato modello “studente”). L’obiettivo è ottenere un modello compatto (il modello distillato) che mantenga prestazioni molto vicine a quelle del colosso di partenza, ma che sia drasticamente più veloce, consumi meno memoria e possa essere eseguito su dispositivi con risorse limitate. In SAIR alcune competizioni vengono lanciate per questo tipo di approccio. Di fatto però Il problema viene spostato più in là perché gli enormi modelli di partenza rimangono e si sviluppano.
Ma il tutto si è fermato a problemi e giochi? Ovviamente no, la curiosità prima di tutto, e la spinta di diverse aziende, hanno portato a sperimentare il passo successivo: non solo problemi più difficili ma dimostratori automatici.
Sebbene la “cassetta degli attrezzi” (LLM + Verificatore + RL) dei dimostratori automatici sia la stessa le strategie di allenamento divergono a causa della diversa natura degli obiettivi. La distinzione tecnica principale risiede nel modo in cui viene gestito lo spazio di ricerca e la conoscenza pregressa. Nei dimostratori automatici (ATP) Il modello viene allenato pesantemente sulla selezione delle premesse. In una libreria formale (come mathlib), e nella letteratura matematica reperibile in rete, esistono decine di migliaia di teoremi e dimostrazioni abbinate. L’algoritmo deve imparare a “pescare” quello giusto al momento giusto. L’allenamento si concentra sulla capacità di navigare in un archivio enorme di fatti già verificati. Di conseguenza il segnale di premio (reward) viene dato per la chiusura di un ramo di una prova complessa. Il modello viene ricompensato se riesce a trovare una “scorciatoia logica” che colleghi la tesi a teoremi già esistenti.
Nei dimostratori automatici, per procurarsi i dati necessari, l’allenamento tecnico punta molto sull’auto-formalizzazione. Si insegna al modello a tradurre i libri di testo di analisi, topologia o geometria in codice Lean, usando poi il verificatore per confermare se la traduzione ha senso logico. Occorre poi ottimizzare il recupero dei teoremi (“la memoria”). Una volta che il modello è stato addestrato, il processo di risoluzione di un nuovo problema non è una semplice “risposta” immediata, ma una vera e propria operazione di ricerca strutturata.
I risultati sono, a volte, sorprendenti; in alcuni casi, come per alcune soluzioni dei problemi di Erdös, ci si accorge che provengono dalla letteratura memorizzata, in altri casi appaiono come la combinazione di pezzi presi qua e la (in fondo è una operazione che accade di svolgere anche ai matematici professionisti). Ancora sorge la domanda di quale sia la strada seguita, qui nemmeno l’LLM te lo sa spiegare, seguire le tracce è opera titanica. Trovare dei principi di base non pare possibile.
Due iniziative interessanti sorte per indagare su questi ultimi aspetti. La prima è FrontierMath: nata per valutare l’IA rispetto alla ricerca matematica avanzata. Questo programma è composto da due elementi: FrontierMath Tiers 1-4, un benchmark di problemi inediti di alta difficoltà, redatti e sottoposti a revisione tra pari da matematici esperti; e Open Problems, una raccolta di problemi di ricerca che restano irrisolti per i matematici. Per questi ultimi, allo stato attuale, un solo problema è stato risolto e riguarda la costruzione di un particolare ipergrafo (compito che, una volta formalizzato, ha potuto giovarsi dell’enorme capacità di calcolo a disposizione). In ogni caso le persone coinvolte ritengono che questi dimostratori potranno diventare utili come collaboratori alla ricerca, qualcuno parla di co-piloti nella ricerca matematica.
La seconda riguarda invece un progetto di Timothy Gowers (medaglia Fields nel 1998) finanziato nell’ambito di AI for Math. Il progetto vuole migliorare l’uso dell’IA in matematica creando un database strutturato di dimostrazioni “motivate”, dove ogni idea è tracciata, e usando tattiche Lean per formalizzarle; questo dovrebbe facilitare addestramento e comprensione dei modelli, migliorandone l’efficacia rispetto agli approcci tradizionali.
In conclusione andrebbe aperto il capitolo importante sulla natura della matematica, e del lavoro del matematico, rispetto ai vari sistemi fin qui descritti. Di certo la matematica non è solo dimostrazione e linguaggio. Un riferimento fra tutti è Il celebre dibattito nella filosofia della matematica del Novecento che vide contrapposti l’approccio formalista di David Hilbert e la visione intuizionista e pragmatica di Henri Poincaré. Anche il modo di procedere di un matematico è vario e difficilmente riducibile, consumo energetico a parte, al sistema sopra descritto. Certo, avere sulla scrivania, l’accesso a gran parte della letteratura matematica, teoremi, e risultati e poter fare una navigazione intelligente è una possibilità enorme. Occorre saper fare le domande giuste, e, ancor prima, avere delle domande. Credo sia un dibattito interessante da rispolverare che lascio, spero, come possibilità aperta, soprattutto se l’interesse si sposta in ambito educativo e scolastico.
Interessante poi che in matematica per alcuni risultati una dimostrazione non basta: si cercano idee alternative, strade differenti e, spesso, questo modo di fare obbliga a nuove costruzioni e fatti interessanti. Lo stesso Erdös è un testimone di questo con la sua raccolta di dimostrazioni belle, e perfette di vari risultati (si veda la raccolta nel testo Proofs from the BOOK edito da M. Aigner e G.M. Ziegler). Non aspettiamoci questo da un LLM, anzi possiamo chiedergli se concorda con Jean Leray: ”La scienza non si apprende: si comprende. Non è lettera morta e i libri non ne assicurano la perpetuità: essa è un pensiero vivente. Per interessarsene, e poi padroneggiarla, il nostro spirito deve, opportunamente guidato, riscoprirla, così come il nostro corpo ha dovuto rivivere, nel seno materno, l’evoluzione che ha creato la nostra specie; non in tutti i suoi dettagli, ma nel suo schema.”
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.




")

")

")

")








 to Watch: StanDoesMath")
Trackback/Pingback