In questo nuovo episodio di Radice di Pop facciamo un salto con Massimo Martone nel mondo delle piattaforme di streaming, con particolare attenzione ai medical drama. Sfidiamo chiunque a non aver visto almeno un episodio di titoli come New Amsterdam, The Good Doctor, Chicago Med e compagnia ospedaliera! Ok, ma che c’entra la matematica?
Cosa faremo?
I medical drama rappresentano un genere televisivo in costante espansione. Anche in Italia, dove inizialmente c’era una certa diffidenza, queste serie sono ormai entrate stabilmente nelle nostre case, al punto che abbiamo deciso di produrne una tutta nostra: Doc: Nelle tue mani. Quel mix irresistibile di relazioni sentimentali, casi clinici e dinamiche professionali ha creato un legame profondo con il pubblico, al punto da farci sentire parte integrante di quei mondi ospedalieri, pur restando comodamente seduti sul divano. Proprio questo intreccio narrativo è stato oggetto di uno studio accademico condotto da Marta Rocchi e Guglielmo Pescatori, docenti dell’Università di Bologna. I due ricercatori hanno analizzato otto medical drama prodotti tra il 2005 e il 2020, concentrandosi proprio su tre aspetti chiave: relazioni amorose, casi clinici e rapporti professionali. Ma cosa accomuna davvero queste serie? Esistono strutture ricorrenti? Modelli narrativi simili?
E se creassimo i Mathematical Drama!?
In che modo?
L’obiettivo dell’articolo di ricerca dei due bolognesi, che riassumeremo quest’oggi, è stato costruire un modello quantitativo della struttura narrativa dei medical drama, basato su tre assi portanti: l’analisi dei contenuti, una procedura di clustering, e la modellizzazione di quello che potremmo definire il “bioma narrativo”, ovvero la distribuzione del tempo dedicato a ciascuna isotopia narrativa.Piccolo glossario per i non addetti ai lavori:
Clustering: si tratta di una tecnica di analisi dei dati che permette di raggruppare elementi simili in base a una nozione di distanza tra loro. L’obiettivo è individuare gruppi coerenti all’interno di un insieme di dati. Nel nostro caso, episodi o segmenti narrativi simili tra loro per struttura, contenuto o funzione narrativa. Per chi volesse approfondire, consigliamo questo articolo che introduce il tema in modo più tecnico.
Isotopia: in semiotica, un’isotopia è una linea di coerenza semantica che attraversa un testo, un “filo rosso” che permette al lettore o spettatore di orientarsi nel significato. Nei medical drama, ad esempio, possiamo identificare isotopie legate ai casi clinici, ai rapporti sentimentali tra i protagonisti, o alle dinamiche di potere all’interno dell’ospedale. Analizzare quanto tempo narrativo viene dedicato a ciascuna di queste isotopie ci permette di tracciare la “mappa genetica” della serie.
Con questo approccio vogliamo rispondere a una domanda precisa: esiste una struttura narrativa ricorrente nei medical drama contemporanei? E, se sì, possiamo descriverla con gli strumenti della matematica e dell’analisi dei dati?
Esempio di un algoritmo di clustering
Modellizzazione del problema
Iniziamo ora a modellizzare il problema. Assoceremo a ogni episodio una tripla di numeri naturali che rappresentano quanto spazio narrativo è dedicato a ciascuna delle tre isotopie individuate:
MC (Medical Case): l’isotopia legata ai casi clinici;
PP (Professional Plot): quella che riguarda le relazioni lavorative e le dinamiche professionali;
SP (Sentimental Plot): le relazioni intime e affettive tra i personaggi.
Per ogni episodio assegneremo un valore numerico a ciascuna di queste variabili, secondo una scala da 0 a 6, tale che la loro somma sia sempre pari a 6: \( \#MC + \#PP + \#SP = 6 \)
In questo modo otteniamo una semplice ma utile normalizzazione, che ci permette di confrontare episodi diversi anche se hanno durate differenti. Un esempio: se un episodio è completamente centrato sul caso clinico della settimana, con scarsa o nulla attenzione agli intrecci professionali o sentimentali, avremo: MC=6 PP=0 SP=0 Ogni episodio, quindi, è rappresentato da una tripla (MC, PP, SP) che vive nello spazio delle soluzioni intere non negative dell’equazione \( MC + PP + SP = 6 \)
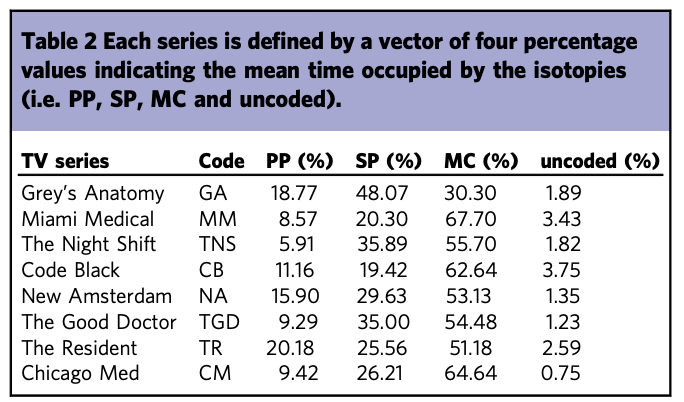
Qui trovate una tabella riassuntiva in termini percentuali dell’analisi effettuata ricavata dall’articolo che stiamo studiando.
A questo punto ci chiediamo: è possibile costruire un clustering efficace che permetta di catalogare gli episodi analizzati? Per capirlo, dobbiamo prima verificare se i dati che abbiamo a disposizione mostrano effettivamente una tendenza al raggruppamento (cluster tendency). In altre parole: gli episodi si distribuiscono in modo uniforme nello spazio narrativo, o si aggregano naturalmente in zone distinte?
Statistica di Hopkins
Per rispondere a questa domanda, impieghiamo la statistica di Hopkins, un test d’ipotesi utilizzato per valutare la non casualità della distribuzione dei punti nello spazio, e quindi l’effettiva propensione del dataset alla formazione di cluster. Vediamo insieme un suo caso generale:
Supponiamo di avere un dataset di \( n \) punti reali \( p_1, p_2, \ldots, p_n \) presi in uno spazio \( R^d \), che chiameremo \(D \). Estraiamo da questo dataset un campione, cioè un dataset \(P \) di \(m\) punti con \(m<n\) scelti in modo random tra gli elementi di \(D \). Per ciascun punto \( p_i \in P \), si calcola la distanza dal punto più vicino nel dataset originale \( D \), ovvero:
$$
\ x_i = \min_{v \in D \setminus \{p_i\}} \ dist(p_i, v)
$$
Si generano poi \( m \) punti casuali \( q_1, q_2, \ldots, q_m \) distribuiti in modo uniforme nella regione di \( R^d \) intorno a \( D \). Per ciascun \( q_i \), si cerca la distanza dal punto di D più vicino:
$$
\ y_i = \min_{v \in D } \ dist(q_i, v)
$$
La statistica di Hopkins è allora calcolata come:
$$
H = \frac{\sum_{i=1}^{m} y_i}{\sum_{i=1}^{m} x_i + \sum_{i=1}^{m} y_i}
$$
Se le distanze calcolate sono più o meno le stesse sia per i punti generati che per quelli campionati allora H≈0.5. Questo implica che il dataset ha una distribuzione random.
Se H→1, vuol dire che le distanze \(x_i \) sono molto piccole e quindi il dataset mostra una forte tendenza al clustering.
Se H→0, i punti sono regolarmente distribuiti (ad esempio su una griglia), ma non clusterizzati.
Nel nostro caso: lavorando in \( R^3 \) e considerando come dataset iniziale i dati raccolti visionando le serie televisive, abbiamo ottenuto un valore di Hopkins ≈ 0.634. Un risultato del genere suggerisce una moderata tendenza al clustering, abbastanza forte da giustificare l’applicazione di un algoritmo di clustering.
Clustering
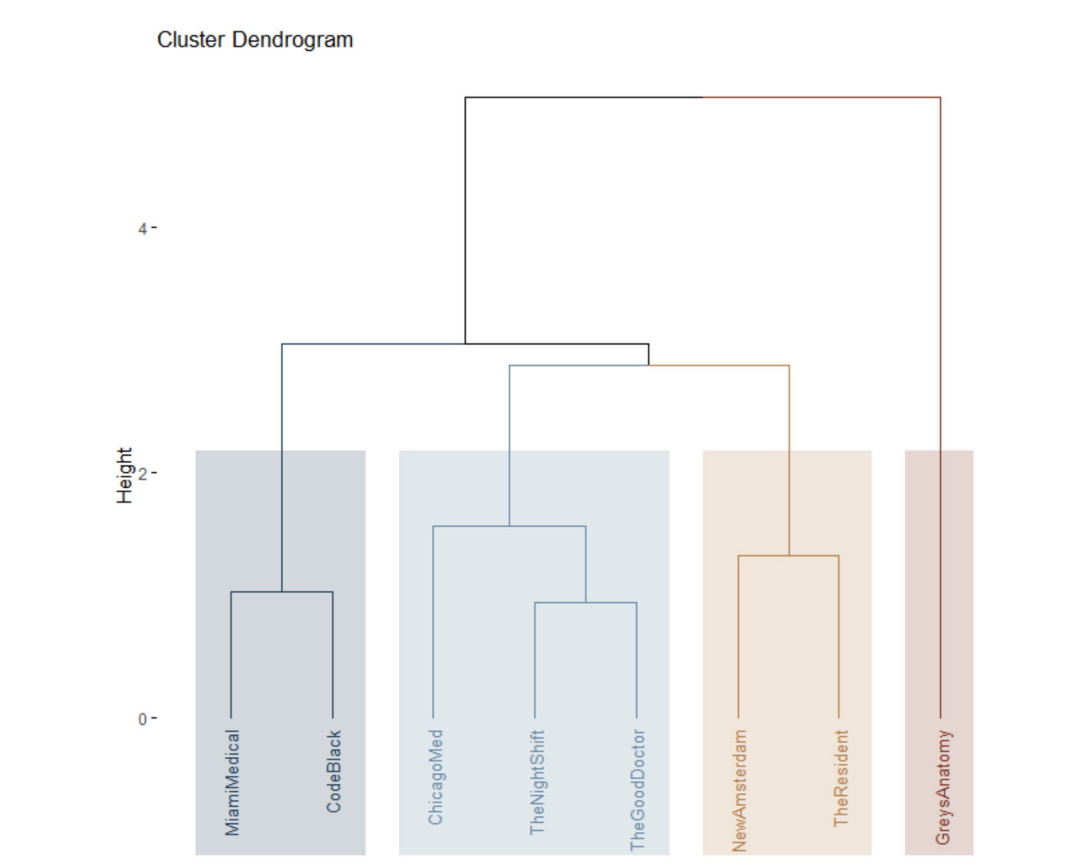
Abbiamo scelto di applicare un algoritmo di clustering gerarchico top-down: all’inizio tutti gli elementi sono in uno stesso cluster, che viene via via suddiviso isolando in un nuovo cluster gli elementi maggiormente dissimili dal gruppo. Il risultato è visualizzabile con una struttura ad albero (dendrogramma) che rappresenta le relazioni di somiglianza tra i cluster (per noi le serie). Come si può osservare dal dendrogramma riportato di seguito, Grey’s Anatomy risulta essere la serie più dissimile rispetto alle altre, posizionandosi come un “outlier” nella gerarchia dei cluster:
Figura 3 dell’articolo di ricerca: risultati del clustering gerarchico
Dall’analisi di clustering abbiamo potuto classificare le stagioni delle serie televisive medical drama in quattro gruppi principali, ciascuno caratterizzato da un equilibrio differente tra componente sentimentale (SP), medico-clinica (MC) e professionale (PP):
Gruppo A, Gruppo B, Gruppo C e Gruppo D
Gruppo A – Sentimentale dominante Include stagioni in cui la sfera emotiva e relazionale tra i personaggi è centrale e occupa la maggior parte dello spazio narrativo. Il sentimental plot (SP) prevale nettamente su quello medico (MC) e professionale (PP). È la cosiddetta “soap formula”, in cui le vicende sentimentali diventano il motore principale della narrazione, spesso con relazioni amorose complicate, triangoli, tradimenti e drammi personali. Esempio: Grey’s Anatomy, stagioni 4-7.
Gruppo B – Casi clinici centrali Raggruppa stagioni in cui la trama è dominata dai casi medici (MC), presentati come sfide da risolvere in ogni episodio, con poco spazio dedicato alla vita privata dei medici. Questa è la “anthology formula”, che ricalca la struttura procedural tradizionale: un caso nuovo per episodio, spesso in tempo reale, con attenzione quasi documentaristica. Esempio: Code Black.
Gruppo C–Bilanciato tra MC e SP Comprende stagioni con un equilibrio relativamente stabile tra vicende emotive e casi clinici. È ciò che lo studio definisce come la “doctors and patients formula”, in cui le due dimensioni si intrecciano armonicamente: le storie dei pazienti fanno da specchio o innesco per i problemi personali dei medici. Esempio: Chicago Med
Gruppo D – Professionale dominante Comprende stagioni dove emerge la dimensione etica, sociale e gestionale della medicina. In queste stagioni, il professional plot (PP) ha un peso sopra la media (16–19%), mentre l’emotività personale è mantenuta più contenuta. Si parla di “social formula”: la narrazione indaga i conflitti di potere, le politiche sanitarie, la burocrazia e la lotta contro il sistema. Esempio: alcune stagioni di House M.D
Conclusioni
L’analisi conferma ciò che molti spettatori percepiscono intuitivamente: le serie medical drama condividono un linguaggio comune, ma non si riducono mai a una formula rigida. Al contrario, si muovono in uno spazio narrativo ampio, dove il peso delle relazioni, della tensione clinica e della dimensione professionale può variare in modo significativo, anche all’interno di una stessa serie. Il clustering delle stagioni ci restituisce una mappa di questi equilibri: esistono stagioni fortemente sentimentali, altre dominate da casi clinici, altre ancora che oscillano tra i due poli. Ma ciò che sorprende di più è la capacità di ogni serie di reinventarsi senza tradirsi, spostandosi da un cluster all’altro pur rimanendo riconoscibile. Un equilibrio sottile tra innovazione e coerenza, tra emozione e procedura. In un’epoca in cui i generi televisivi sembrano sempre più ibridi, questo tipo di analisi ci aiuta non solo a capire meglio le serie che guardiamo, ma anche a riconoscere le strutture narrative che ci tengono incollati allo schermo, puntata dopo puntata, stagione dopo stagione.
P.S. Se sei appassionato di statistica e vuoi saperne di più sul clustering, il miglior testo in assoluto è disponibile gratuitamente, per volontà degli autori, e puoi trovarlo qui. Se poi sei curioso di esplorare nel dettaglio il lavoro svolto, ti consiglio di dare un’occhiata a questo link: troverai tutti i dati utilizzati nell’articolo di ricerca, pronti per essere analizzati.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.





. March 15, 2016")



. March 15, 2016")







 to Watch: StanDoesMath")