Quella sensazione di sentirci “spiati” dal nostro supermercato, o da Facebook, che ci consigliano prodotti vicini ai nostri gusti. Continua il nostro viaggio nei big data… (trovate qui la prima puntata).
Non si pensi che i big data siano ristretti ai social network piuttosto che alle azioni mirate di marketing, il loro utilizzo sta crescendo “selvaggiamente” in numerosissime discipline: dalla biologia molecolare alla genomica, dalla scienza dei materiali alle strategie di estrazione del petrolio e dei gas naturali, dalle scienze sociali all’astrofisica.
Un altro esempio interessante, che ha creato un notevole dibattito sull’utilizzo dei big data, riguarda l’epidemiologia. Nel 2009 appare infatti sulla prestigiosa rivista Nature uno studio in cui si “pretendeva” di prevedere l’andamento di epidemie influenzali. Il problema della descrizione precoce della dinamica di tali epidemie è certamente uno dei problemi importanti dell’epidemiologia e della gestione della salute pubblica. Riuscire a mitigare e prevedere l’impatto di eventi del genere è di grande interesse sociale, sanitario ed economico. Lo studio in questione si proponeva di arrivare a una previsione di tale dinamica in modo rapido e con un basso costo attraverso l’analisi di big-data relativi alle ricerche degli utenti web attraverso due dei principali motori di ricerca (google e Yahoo).
Ovviamente la selezione veniva fatta attraverso parole chiave nelle ricerche che potevano essere in relazione con l’influenza: sintomi, medicinali, complicazioni e via dicendo. I risultati sono apparsi sorprendenti: il metodo proposto appariva in grado di monitorare l’andamento dell’influenza in una popolazione fornendo anche una stima settimanale dell’attività influenzale in ogni regione degli Stati Uniti (con un ritardo nella segnalazione di circa un giorno). Il metodo introdotto appariva decisamente più efficiente rispetto ai metodi di previsione tradizionali come quello adottato dal CDC (US Centers for Disease Control and Prevention) e basato su dati sia virologici che clinici (basti pensare che la segnalazione dell’andamento dell’epidemia influenzale da parte del CDC viene fornita con una o due settimane di ritardo). Anche negli anni successivi il metodo GFT (Google Flu Trends) riesce a produrre ottime stime dell’andamento di malattie influenzali o simili e viene sperimentato anche fuori dagli Stati Uniti.
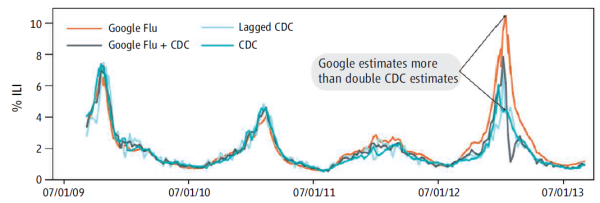
Previsioni a confronto tra il nuovo metodo Google flu trends (GFT) ed il metodo classico del Centro CDC nel periodo 2004-2008 (questi dati sono serviti per calibrare il metodo GFT).
L’entusiasmo per l’uso dei big data in epidemiologia cresce e sistemi simili vengono introdotti (ovviamente anche l’ormai immancabile Twitter viene coinvolto ma con risultati modesti). Tale entusiasmo dura fino al Febbraio 2013, quando sempre su Nature si segnala infatti che la previsione del numero di visite mediche dovute a sindromi di tipo influenzale secondo il sistema GFT risulta essere il doppio rispetto alla previsione, poi risultata più vicina alla realtà, fatta dal CDC. Si apre una interessante discussione che mette in evidenza la potenzialità in ambito scientifico dei big data ma anche la necessità di evitare la “Big data hubris”: occorre una interazione con metodi tradizionali (non solo dati, anche se tanti, ma anche modelli e comprensione delle variabili in gioco).
Le possibilità scientifiche offerte dai big-data appaino enormi ma occorrono metodologie adeguate.
La previsione sbagliata da GFT nel 2013 con una stima molto piu’ alta rispetto ai metodi tradizionali.
Ronald Coifman, matematico in forza alla Yale University, auspica (forse esagerando?) per i big data l’avvento di una rivoluzione della stessa portata che ebbe l’introduzione del calcolo infinitesimale nel panorama scientifico del XVII secolo e crede che la matematica moderna, in particolar modo la geometria, possa aiutare a identificare le strutture nascoste all’interno dei grossi archivi.
È proprio un’intuizione geometrica quella che sta alla base della TDA (topological data analysis) un insieme di tecniche sviluppate per l’analisi di grossi dataset, da Gunnar Carlsson matematico di Stanford. L’idea di base è che i dati possano essere visti come punti di un opportuno spazio topologico, ossia di uno spazio in cui è ben definita una nozione di vicinanza, in modo che più i punti sono vicini tra loro più i dati che rappresentano sono simili. Così facendo si riescono a “codificare” archivi di dimensioni alte in una struttura di grafo: una collezione di punti e di connessioni tra di essi che ne codificano le mutue distanze. Questa rappresentazione ha il vantaggio di ridurre la dimensionalità dei dati di partenza, permettendo anche di visualizzare i dataset e di coglierne, anche visivamente, la struttura.
Per spiegare i vantaggi offerti da questa possibilità Carlsson immagina di dover cercare un martello in un garage immerso completamente nel buio e di avere a disposizione soltanto una piccola torcia per far luce.
Alla fine dopo aver illuminato ogni possibile angolo forse si riuscirà a trovare il martello, ma non sarebbe forse meglio accendere direttamente la luce della stanza in modo da avere un punto di vista globale? In questo modo non solo troveremo il martello ma anche lo scatolino dei chiodi lì accanto. Processare i dati con la TDA sarebbe quindi come accendere la luce sui nostri dataset per coglierne a colpo d’occhio l’organizzazione interna.
Le fonti di luce con cui la TDA riesce a fare chiarezza nel groviglio dei big data appartengono alla costellazione della geometria algebrica che, semplificando, si occupa di tradurre proprietà topologiche nel linguaggio dell’Algebra, col grande vantaggio di renderle accessibili per una elaborazione con un computer.
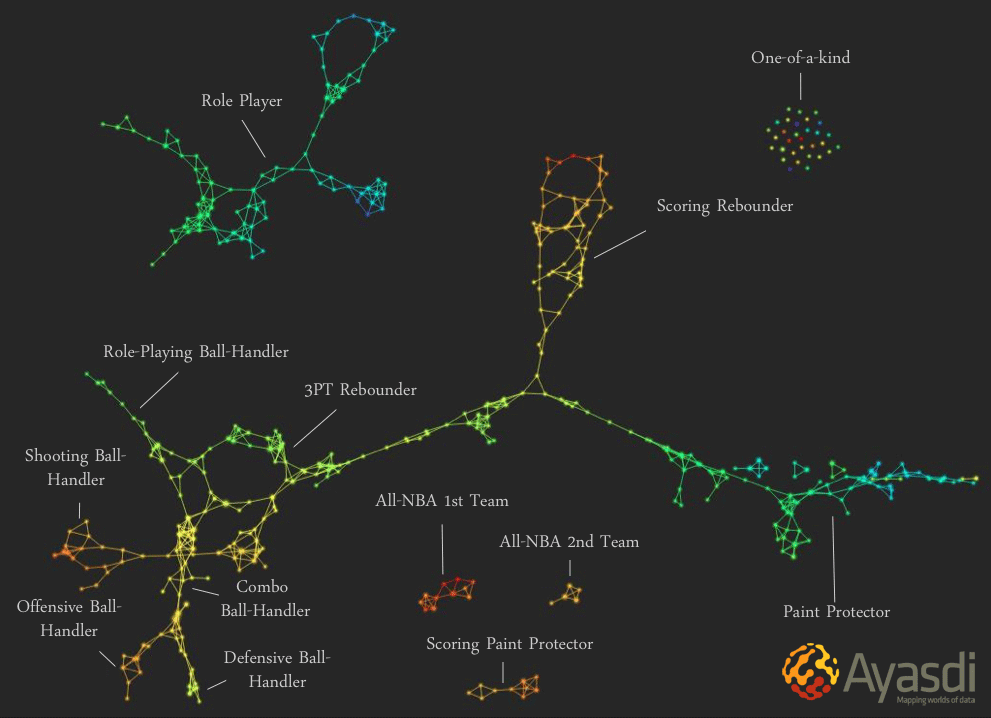
Certamente la rappresentazione topologica di dimensione bassa prodotta dalla TDA, avverte Carlsson, non potrà essere completamente fedele ai dati, ma se si al suo interno si evidenziano delle caratteristiche topologiche interessanti, quasi sicuramente queste saranno presenti anche nei dati originali, e saranno fondamentali per comprenderne meglio la natura. La TDA è stata con successo applicata alla genomica, ma la sua flessibilità le consente di essere applicata a svariati campi d’indagine tra cui l’analisi del gioco dei professionisti NBA di cui si parlava all’inizio. Ma come funziona? Cercheremo di dare qualche altra indicazione prossimamente, almeno per i più curiosi.
La nuova classificazione dei giocatori NBA in base alle dinamiche utilizzate nel gioco, ogni nodo rappresenta uno o più giocatori considerati vicini, gli archi di collegamento indicano similarità (per esempio un arco congiunge nodi che hanno giocatori in comune)
Luca Magri, Giovanni Naldi
Dipartimento di Matematica “F. Enriques”, Università degli studi di Milano
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.




")

")

")

")







")

